Elastic Hadoop Clusters with Amazon's Elastic Block Store
I gave a talk on Tuesday at the first Hadoop User Group UK about Hadoop and Amazon Web services - how and why you can run Hadoop with AWS. I mentioned how integrating Hadoop with Amazon's "Persistent local storage", which Werner Vogels had pre-announced in April, would be a great feature to have to enable truly elastic Hadoop clusters that you could stop and start on demand.
Well, the very next day Amazon launched this service, called Elastic Block Store (EBS). So in this post I thought I'd sketch out how an elastic Hadoop might work.
A bit of background. Currently there are three main ways to use Hadoop with AWS:
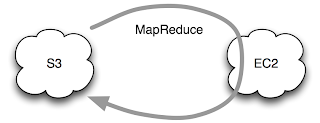 In this set up, the data resides on S3, and the MapReduce daemons run on a temporary EC2 cluster for the duration of the job run. This works, and is especially convenient if you've already store your data on S3, but you don't get any data locality. Data locality is what enables the magic of MapReduce to work efficiently - the computation is scheduled to run on the machine where the data is stored, so you get huge savings in not having to ship terabytes of data around the network. EC2 does not share nodes with S3 storage, in fact they are often in different data centres, so performance is nowhere near as good as a regular Hadoop cluster where the data in stored in HDFS (see 3. below).
In this set up, the data resides on S3, and the MapReduce daemons run on a temporary EC2 cluster for the duration of the job run. This works, and is especially convenient if you've already store your data on S3, but you don't get any data locality. Data locality is what enables the magic of MapReduce to work efficiently - the computation is scheduled to run on the machine where the data is stored, so you get huge savings in not having to ship terabytes of data around the network. EC2 does not share nodes with S3 storage, in fact they are often in different data centres, so performance is nowhere near as good as a regular Hadoop cluster where the data in stored in HDFS (see 3. below).
It's not all doom and gloom, as the bandwidth between EC2 and S3 is actually pretty good, as Rightscale found when they did some measurements.
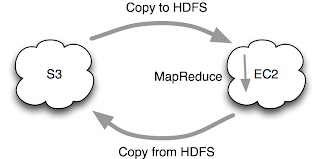 Data is stored on S3 but copied to a temporary HDFS cluster running on EC2. This is just a variation of the previous set-up, which is good if you want to run several jobs against the same input data. You save by only copying the data across the network once, but you pay a little more due to HDFS replication.
Data is stored on S3 but copied to a temporary HDFS cluster running on EC2. This is just a variation of the previous set-up, which is good if you want to run several jobs against the same input data. You save by only copying the data across the network once, but you pay a little more due to HDFS replication.
The bottleneck is still copying the data out of S3. (Copying the results back into S3 isn't usually as bad as the output is often an order or two of magnitude smaller than the input.)
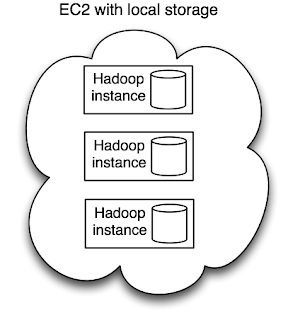 Of course, you could just run a Hadoop cluster on EC2 and store your data there (and not in S3). In this scenario, you are committed to running your EC2 cluster long term, which can prove expensive, although the locality is excellent.
Of course, you could just run a Hadoop cluster on EC2 and store your data there (and not in S3). In this scenario, you are committed to running your EC2 cluster long term, which can prove expensive, although the locality is excellent.
These three scenarios demonstrate that you pay for locality. However, there is a gulf between S3 and local disks that EBS fills nicely. EBS does not have the bandwidth of local disks, but it's significantly better than S3. Rightscale again:
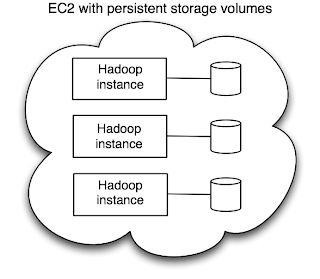 The main departure from the current Hadoop on EC2 approach is the need to maintain a map from storage volume to node type: i.e. we need to remember which volume is a master volume (storing the namenode's data) and which is a worker volume (storing the datanode's data). It would be nice if you could just start up EC2 instances for all the volumes, and have them figure out which is which, but this might not work as the master needs to be started first so its address can be given to the workers in their user data. (This choreography problem could be solved by introducing ZooKeeper, but that's another story.) So for a first cut, we could simply keep two files (locally, or on S3 or even SimpleDB) called master-volumes, and worker-volumes, which simply list the volume IDs for each node type, one per line.
The main departure from the current Hadoop on EC2 approach is the need to maintain a map from storage volume to node type: i.e. we need to remember which volume is a master volume (storing the namenode's data) and which is a worker volume (storing the datanode's data). It would be nice if you could just start up EC2 instances for all the volumes, and have them figure out which is which, but this might not work as the master needs to be started first so its address can be given to the workers in their user data. (This choreography problem could be solved by introducing ZooKeeper, but that's another story.) So for a first cut, we could simply keep two files (locally, or on S3 or even SimpleDB) called master-volumes, and worker-volumes, which simply list the volume IDs for each node type, one per line.
Assume there is one master running the namenode and jobtracker, and n worker nodes each running a datanode and tasktracker.
To create a new cluster
Building this would be a great project to work on - I hope someone does it!
Well, the very next day Amazon launched this service, called Elastic Block Store (EBS). So in this post I thought I'd sketch out how an elastic Hadoop might work.
A bit of background. Currently there are three main ways to use Hadoop with AWS:
1. MapReduce with S3 source and sink
 In this set up, the data resides on S3, and the MapReduce daemons run on a temporary EC2 cluster for the duration of the job run. This works, and is especially convenient if you've already store your data on S3, but you don't get any data locality. Data locality is what enables the magic of MapReduce to work efficiently - the computation is scheduled to run on the machine where the data is stored, so you get huge savings in not having to ship terabytes of data around the network. EC2 does not share nodes with S3 storage, in fact they are often in different data centres, so performance is nowhere near as good as a regular Hadoop cluster where the data in stored in HDFS (see 3. below).
In this set up, the data resides on S3, and the MapReduce daemons run on a temporary EC2 cluster for the duration of the job run. This works, and is especially convenient if you've already store your data on S3, but you don't get any data locality. Data locality is what enables the magic of MapReduce to work efficiently - the computation is scheduled to run on the machine where the data is stored, so you get huge savings in not having to ship terabytes of data around the network. EC2 does not share nodes with S3 storage, in fact they are often in different data centres, so performance is nowhere near as good as a regular Hadoop cluster where the data in stored in HDFS (see 3. below).It's not all doom and gloom, as the bandwidth between EC2 and S3 is actually pretty good, as Rightscale found when they did some measurements.
2. MapReduce from S3 with HDFS staging
 Data is stored on S3 but copied to a temporary HDFS cluster running on EC2. This is just a variation of the previous set-up, which is good if you want to run several jobs against the same input data. You save by only copying the data across the network once, but you pay a little more due to HDFS replication.
Data is stored on S3 but copied to a temporary HDFS cluster running on EC2. This is just a variation of the previous set-up, which is good if you want to run several jobs against the same input data. You save by only copying the data across the network once, but you pay a little more due to HDFS replication.The bottleneck is still copying the data out of S3. (Copying the results back into S3 isn't usually as bad as the output is often an order or two of magnitude smaller than the input.)
3. HDFS on Amazon EC2
 Of course, you could just run a Hadoop cluster on EC2 and store your data there (and not in S3). In this scenario, you are committed to running your EC2 cluster long term, which can prove expensive, although the locality is excellent.
Of course, you could just run a Hadoop cluster on EC2 and store your data there (and not in S3). In this scenario, you are committed to running your EC2 cluster long term, which can prove expensive, although the locality is excellent.These three scenarios demonstrate that you pay for locality. However, there is a gulf between S3 and local disks that EBS fills nicely. EBS does not have the bandwidth of local disks, but it's significantly better than S3. Rightscale again:
The bottom line though is that performance exceeds what we’ve seen for filesystems striped across the four local drives of x-large instances.
Implementing Elastic Hadoop
 The main departure from the current Hadoop on EC2 approach is the need to maintain a map from storage volume to node type: i.e. we need to remember which volume is a master volume (storing the namenode's data) and which is a worker volume (storing the datanode's data). It would be nice if you could just start up EC2 instances for all the volumes, and have them figure out which is which, but this might not work as the master needs to be started first so its address can be given to the workers in their user data. (This choreography problem could be solved by introducing ZooKeeper, but that's another story.) So for a first cut, we could simply keep two files (locally, or on S3 or even SimpleDB) called master-volumes, and worker-volumes, which simply list the volume IDs for each node type, one per line.
The main departure from the current Hadoop on EC2 approach is the need to maintain a map from storage volume to node type: i.e. we need to remember which volume is a master volume (storing the namenode's data) and which is a worker volume (storing the datanode's data). It would be nice if you could just start up EC2 instances for all the volumes, and have them figure out which is which, but this might not work as the master needs to be started first so its address can be given to the workers in their user data. (This choreography problem could be solved by introducing ZooKeeper, but that's another story.) So for a first cut, we could simply keep two files (locally, or on S3 or even SimpleDB) called master-volumes, and worker-volumes, which simply list the volume IDs for each node type, one per line.Assume there is one master running the namenode and jobtracker, and n worker nodes each running a datanode and tasktracker.
To create a new cluster
- Create n + 1 volumes.
- Create the master-volumes file and write the first volume ID into it.
- Create the worker-volumes file and write the remaining volume IDs to it.
- Follow the steps for starting a cluster.
- Start the master instance passing it the master-volumes as user data. On startup the instance attaches to the volume it was told to. It then formats the namenode if it isn't already formatted, then starts the namenode, secondary namenode and jobtracker.
- Start n worker instances passing it the worker-volumes as user data. On startup each instance attaches to the volume on line i, where i is the ami-launch-index of the instance. Each instance then starts a datanode and tasktacker.
- If any worker instances failed to start then launch them again.
- Shutdown the Hadoop cluster daemons.
- Detach the EBS volumes.
- Shutdown the EC2 instances.
- Create m new volumes, where m is the size to grow by.
- Append the m new volume IDs to the worker-volumes file.
- Start m worker instances passing it the worker-volumes as user data. On startup each instance attaches to the volume on line n + i, where i is the ami-launch-index of the instance. Each instance then starts a datanode and tasktacker.
Building this would be a great project to work on - I hope someone does it!